



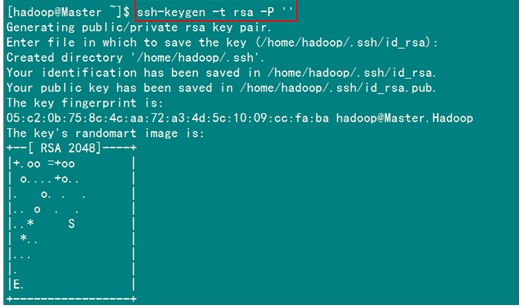
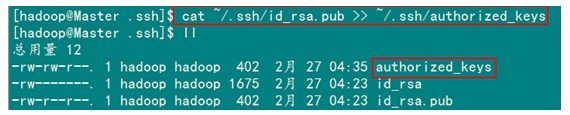
在验证前,需要做两件事儿。第一件事儿是修改文件"authorized_keys"权限(权限的设置非常重要,因为不安全的设置安全设置,会让你不能使用RSA功能),另一件事儿是用root用户设置"/etc/ssh/sshd_config"的内容。使其无密码登录有效。
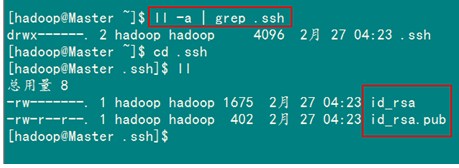
1)修改文件"authorized_keys”

2)设置SSH配置
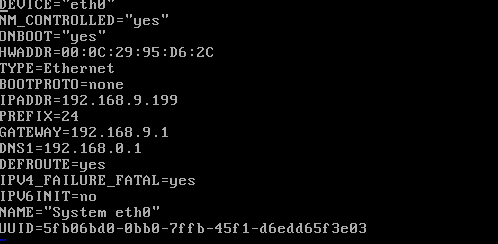
用root用户登录服务器修改SSH配置文件"/etc/ssh/sshd_config"的下列内容

进入配置界面把下面的内容添加到配置里面保存退出

保存配置之后一定要进行文件的从新启动,不然配置的内容是不会有效果的。执行命令
service sshd restart
从启服务之后我们推出root用户,用hadoop用户进行测试
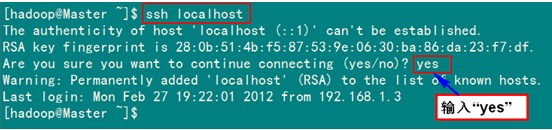
出现上图的效果的时候证明我们已经在本机上配置好了,下面我们就要把公钥复制到我们的Slave1机器上进行配置了,复制的命令如下:
scp ~/.ssh/id_rsa.pub 远程用户名@远程服务器IP:~/

这是我们已经把我们的文件复制到Slave1机器上了,我们可以登录我们Slave系统上查看是否有该文件

这个时候我们发现已经复制过去了。
2)在"/home/hadoop/"下创建".ssh"文件夹
这一步并不是必须的,如果在Slave1.Hadoop的"/home/hadoop"已经存在就不需要创建了,因为我们之前并没有对Slave机器做过无密码登录配置,所以该文件是不存在的。用下面命令进行创建。(备注:用hadoop登录系统,如果不涉及系统文件修改,一般情况下都是用我们之前建立的普通用户hadoop进行执行命令。)
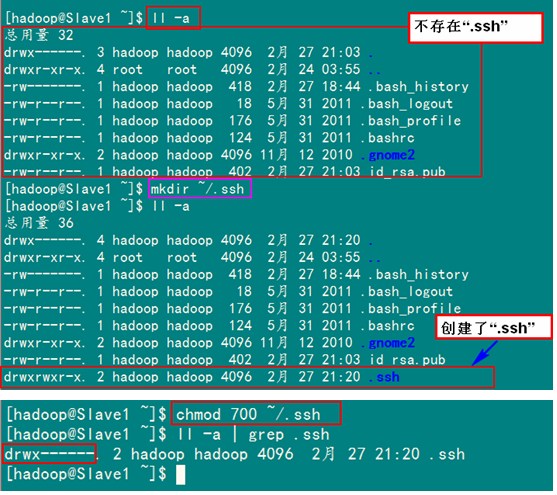
注释:如果不进行,即使你按照前面的操作设置了"authorized_keys"权限,并配置了"/etc/ssh/sshd_config",还重启了sshd服务,在Master能用"ssh localhost"进行无密码登录,但是对Slave1.Hadoop进行登录仍然需要输入密码,就是因为".ssh"文件夹的权限设置不对。这个文件夹".ssh"在配置SSH无密码登录时系统自动生成时,权限自动为"700",如果是自己手动创建,它的组权限和其他权限都有,这样就会导致RSA无密码远程登录失败。
对比上面两张图,发现文件夹".ssh"权限已经变了。
3)追加到授权文件"authorized_keys"
到目前为止Master.Hadoop的公钥也有了,文件夹".ssh"也有了,且权限也修改了。这一步就是把Master.Hadoop的公钥追加到Slave1.Hadoop的授权文件"authorized_keys"中去。使用下面命令进行追加并修改"authorized_keys"文件权限:

4)用root用户修改"/etc/ssh/sshd_config"
具体步骤参考前面Master.Hadoop的"设置SSH配置",具体分为两步:第1是修改配置文件;第2是重启SSH服务。
5)用Master.Hadoop使用SSH无密码登录Slave1.Hadoop
当前面的步骤设置完毕,就可以使用下面命令格式进行SSH无密码登录了。

这个时候我们发现我们已经配置成功了。
(同样的原理我们Slave登录Master也是一样的配置呢,这里图片我是在博客园截的图,他的ip地址和我的是不一样的他的Master是192.168.1.2,Slave1是192.168.1.3。)
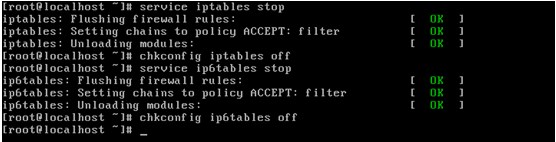
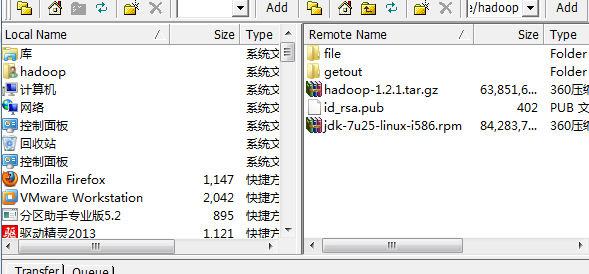
第三部就是java环境的安装了,这里我用的是jdk-7u25-linux-i586.rpm,所有的机器上都要安装JDK,现在就先在Master服务器安装,然后其他服务器按照步骤重复进行即可。安装JDK以及配置环境变量,需要以"root"的身份进行。 首先用root身份登录"Master.Hadoop"后在"/usr"下创建"java"文件夹,再把用SSH_linux上传到"/home/hadoop/"下的"jdk-6u31-linux-i586.bin"复制到"/usr/java"文件夹中。
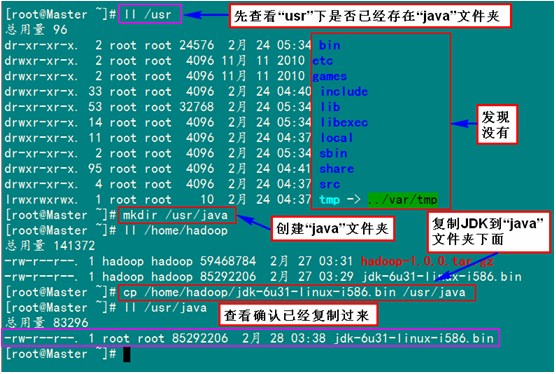
接着进入"/usr/java"目录下通过下面命令使其JDK获得可执行权限,并安装JDK。
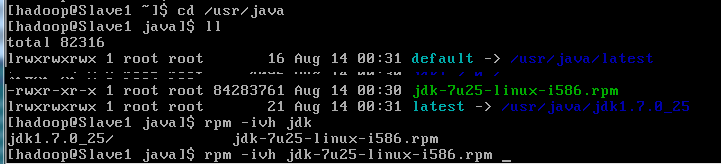
回车就可以进行文件的安装了。
再次执行

这个时候证明我们已经安装完毕了。
java环境安装好了,我们还要配置java的环境,


这个时候我们保持退出,从新启动服务

这个是我们的java就配置完成了,我们可以通过java -version来看我们是否配置成功

这个时候证明我们java环境就配置好了。接下来我们就要把每台服务器都配置好java环境。
第四部是hadoop环境的安装。
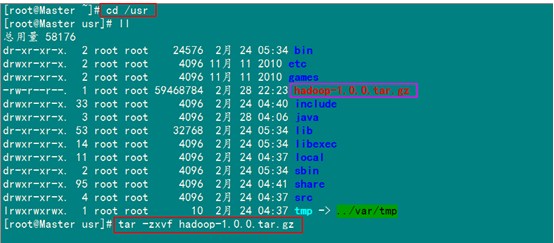
首先用root用户登录"Master.Hadoop"机器,查看我们之前用SSH_linux上传至"/home/Hadoop"上传的"hadoop-1.0.0.tar.gz"。

然后复制到usr文件夹下面

对文件进行解压